
Общие принципы работы сервиса машинного обучения
Сервис машинного обучения (сервис прогнозирования значений справочного поля) использует методы статистического анализа для обучения на основании набора исторических данных. Историческими данными могут быть, например, обращения в службу поддержки за год. При этом используется текст обращения, а также дата и категория контрагента. Результирующим является поле Группа ответственных.
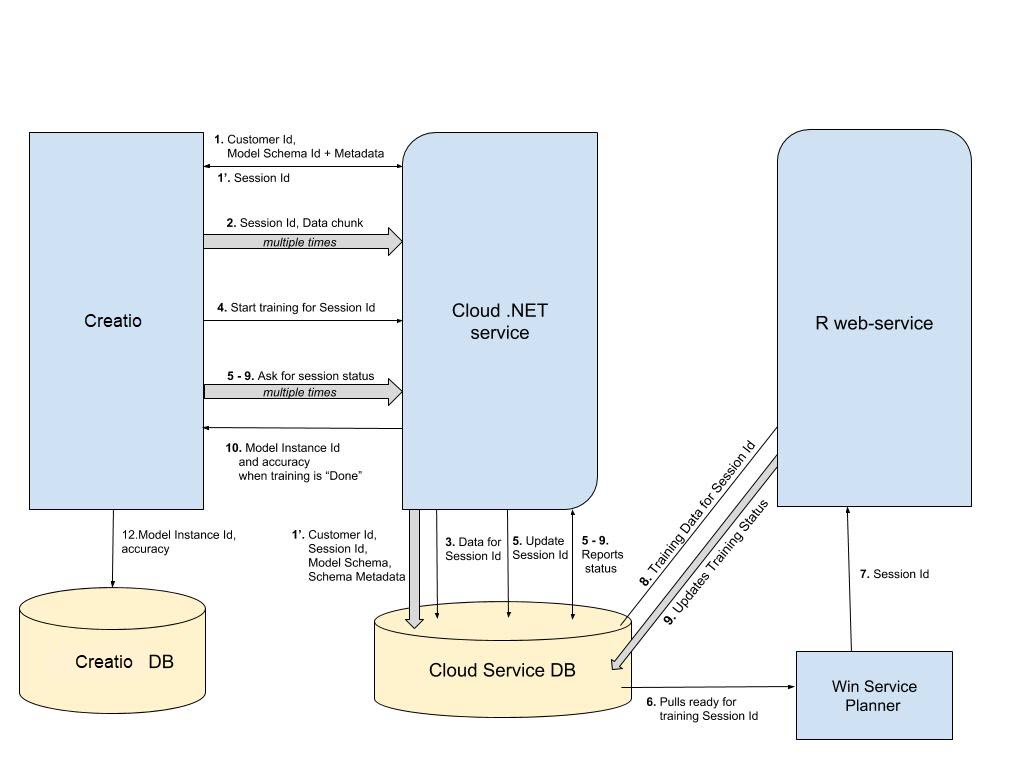
Схема взаимодействия Creatio с сервисом прогнозирования
Существует два основных этапа работы Creatio для каждой модели: обучение и прогнозирование.
Модель прогнозирования — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное решение на основе исторических данных.
Обучение
На этапе обучения выполняется "тренировка" сервиса. Основные шаги обучения:
- Установление сессии передачи данных и обучения.
- Последовательная выборка порции данных для модели и их загрузка в сервис.
- Запрос на постановку в очередь для обучения.
- Training engine для обучения модели обрабатывает очередь, обучает модель и сохраняет ее параметры во внутреннее хранилище.
- Creatio периодически опрашивает сервис для получения статуса модели.
- Как только для статуса модели установлено значение Done — модель готова для прогнозирования.
Прогнозирование
Задача прогнозирования выполняется через вызов облачного сервиса с указанием Id экземпляра модели и данных для прогноза. Результат работы сервиса — набор значений с вероятностями, который сохраняется в Creatio в таблице MLPrediction.
Если существует прогноз в таблице MLPrediction по определенной записи сущности, то на странице записи автоматически отображаются спрогнозированные значения для поля.
Настройки и типы данных Creatio для работы с сервисом прогнозирования
Настройки Creatio
Настройки Creatio, которые необходимо выполнить для работы с сервисом прогнозирования, описаны в статье Заполнить настройки Creatio.
Расширение логики обучения модели
Описанная выше цепочка классов вызывает и создает экземпляры друг друга посредством IOC контейнера Terrasoft.Core.Factories.ClassFactory.
Если необходимо заместить логику какого-либо компонента, то нужно реализовать соответствующий интерфейс. При запуске приложения следует выполнить привязку интерфейса в собственной реализации.
Интерфейсы для расширения логики:
IMLModelTrainerJob — реализация этого интерфейса позволит изменить набор моделей для обучения.
IMLModelTrainer — отвечает за логику загрузки данных для обучения и обновления статуса моделей.
IMLServiceProxy — реализация этого интерфейса позволит выполнять запросы к произвольному предиктивному сервису.
Вспомогательные классы для прогнозирования
Вспомогательные (утилитные) классы для прогнозирования позволяют реализовать два базовых кейса:
- Прогнозирование в момент создания или обновления записи какой-либо сущности на сервере.
- Прогнозирование при изменении сущности на странице записи.
В случае прогнозирования на стороне сервера Creatio — создается бизнес-процесс, который реагирует на сигнал создания/изменения сущности, вычитывает набор полей и вызывает сервис прогнозирования. При получении корректного результата он сохраняет набор значений поля с вероятностями в таблицу MLClassificationResult. При необходимости бизнес-процесс записывает отдельное значение (например, с наибольшей вероятностью) в соответствующее поле сущности.
Составление запросов на выборку данных для модели машинного обучения
Для выборки тренировочных данных или данных для прогнозирования сервиса машинного обучения используется экземпляр класса Terrasoft.Core.DB.Select. Он динамически интерпретируется с помощью Terrasoft.Configuration.ML.QueryInterpreter.
При составлении выражения запроса в качестве аргумента типа Terrasoft.Core.UserConnection в конструкторе Select следует использовать предоставляемую переменную userConnection. Также обязательным в выражении запроса является наличие колонки с псевдонимом “Id” — уникальным идентификатором экземпляра целевого объекта.
Так как выражение Select может быть довольно сложным, то для упрощения его читаемости были добавлены следующие возможности:
- Динамическое добавление типов для интерпретатора.
- Использование локальных переменных.
- Использование утилитного класса Terrasoft.Configuration.QueryExtensions.
Динамическое добавление типов для интерпретатора
Существует возможность динамически добавлять типы для интерпретатора. Для этого класс QueryInterpreter предоставляет методы RegisterConfigurationType и RegisterType. Их можно напрямую использовать в выражении. Например, вместо непосредственного использования идентификатора типа:
можно использовать название константы из динамически зарегистрированного перечисления:
Использование локальных переменных
Существует возможность использовать локальные переменные для предотвращения дублирования кода и более удобного структурирования. Ограничение: тип переменной должен быть статически вычисляем и определяется ключевым словом var.
Например, запрос с повторяющимся использованием делегатов:
можно переписать следующим образом:
Подключение веб-сервиса к функциональности машинного обучения
Задачи машинного обучения (классификация, скоринг, числовая регрессия) или другие подобные задачи (например, прогнозирование оттока клиентов) можно реализовать с помощью веб-сервиса. Эта статья описывает процесс подключения к Creatio пользовательского веб-сервиса, реализующего задачу машинного обучения.
Общий порядок действий при подключении пользовательского веб-сервиса к сервису машинного обучения:
- Создайте веб-сервис — движок машинного обучения.
- Расширьте список задач сервиса машинного обучения.
- Реализуйте модель машинного обучения.
Создание веб-сервиса — движка машинного обучения
Пользовательский веб-сервис должен реализовать контракт для обучения и выполнения прогнозов по существующей модели. Пример контракта можно посмотреть через Swagger сервиса машинного обучения Creatio.
Обязательные методы:
- /session/start — начало сессии обучения модели.
- /data/upload — передача данных в рамках открытой сессии обучения.
- /session/info/get — получение информации о состоянии сессии.
- <пользовательский метод начала обучения> — метод, который будет вызван Creatio по завершении процесса передачи данных. Процесс обучения модели не должен быть завершен до завершения выполнения этого метода. Процесс обучения может длиться произвольное количество времени (десятки минут и даже часы). Когда обучение завершено, метод /session/info/get должен будет вернуть состояние сессии обучения Done или Error в зависимости от результата обучения. Кроме этого, если модель успешно обучена, то необходимо вернуть информацию об экземпляре модели — ModelSummary: тип метрики, значение метрики, идентификатор экземпляра и другие.
- <пользовательский метод прогнозирования> — метод произвольной сигнатуры, который будет выполнять прогнозирование данных на основании идентификатора экземпляра обученной модели.
Процесс разработки веб-сервиса с использованием IDE Microsoft Visual Studio описан в статье.
Расширение списка задач сервиса машинного обучения
Для расширения списка задач машинного обучения в Creatio необходимо дополнить справочник MLProblemType новой записью. Необходимо указать следующие параметры:
- Service endpoint Url — адрес работающего сервиса машинного обучения.
- Training endpoint — путь метода начала обучения.
- Prediction endpoint — путь метода прогнозирования.
Реализация модели машинного обучения
Для настройки и отображения модели машинного обучения, возможно, потребуется расширить схему карточки MLModelPage.
Реализация IMLPredictor
Необходимо реализовать метод Predict, который на вход получит данные, выгруженные из системы по объекту (в виде Dictionary
Реализация IMLEntityPredictor
Необходимо инициализировать свойство ProblemTypeId идентификатором созданной записи в справочнике MLProblemType. Также необходимо реализовать следующие методы:
- SaveEntityPredictedValues — метод получает результат прогнозирования и должен сохранить его для объекта (entity) системы, для которого выполнялось прогнозирование. Если возвращаемое значение типа double или подобно результату классификации, можно воспользоваться методами вспомогательного класса PredictionSaver.
- SavePrediction (опционально) — метод сохраняет результат прогнозирования в привязке к экземпляру обученной модели и идентификатору объекта (entityId). Для базовых задач в системе существуют объекты MLPrediction и MLClassificationResult.
Расширение IMLServiceProxy и MLServiceProxy (опционально)
Можно расширить существующий интерфейс IMLServiceProxy и его реализацию методом прогнозирования для текущей задачи. В частности, класс MLServiceProxy содержит обобщенный метод Predict, который принимает контракты для входящих данных и результата прогнозирования.
Реализация IMLBatchPredictor
В случае, если сервис вызывается с набором данных (500 шт.), следует реализовать интерфейс IMLBatchPredictor. Необходимо реализовать следующие методы:
- FormatValueForSaving — метод возвращает значение, преобразованное для сохранения результата прогноза в базе данных. В случае пакетного прогнозирования для ускорения операции сохранения запись обновляется в базе данных методом Update, а не через экземпляры Entity.
- SavePredictionResult — определяет, как будет сохраняться результат прогнозирования в системе для каждой записи. Для базовых задач в системе существуют объекты MLPrediction и MLClassificationResult.
Использование утилитного класса Terrasoft.Configuration.QueryExtensions
Утилитный класс Terrasoft.Configuration.QueryExtensions предоставляет несколько расширяющих методов для Terrasoft.Core.DB.Select. Это позволяет составлять более компактные запросы.
Для всех расширяющих методов в качестве аргумента object sourceColumn могут быть использованы следующие типы (они будут трансформированы в Terrasoft.Core.DB.QueryColumnExpression):
- System.String — название колонки в формате "TableAlias.ColumnName as ColumnAlias" (где TableAlias и ColumnAlias опциональны) или "*" — все колонки.
- Terrasoft.Core.DB.QueryColumnExpression — будет добавлен без изменений.
- Terrasoft.Core.DB.IQueryColumnExpressionConvertible — будет сконвертировано.
- Terrasoft.Core.DB.Select — будет рассмотрен как подзапрос.
public static Select Cols(this Select select, params object[] sourceColumns)
Добавляет в запрос указанные колонки или подвыражения.
Используя расширяющий метод Cols(), вместо громоздкого выражения:
можно записать:
public static Select Count(this Select select, object sourceColumn)
Добавляет в запрос агрегирующую колонку для вычисления количества непустых значений.
Например, вместо:
можно записать:
public static Select Coalesce(this Select select, params object[] sourceColumns)
Добавляет в запрос колонку с функцией определения первого значения, не равного NULL.
Например, вместо:
можно записать:
public static Select DateDiff(this Select select, DateDiffQueryFunctionInterval interval, object startDateExpression, object endDateExpression)
Добавляет в запрос колонку с определением разницы дат.
Например, вместо:
можно записать:
public static Select IsNull(this Select select, object checkExpression, object replacementValue)
Добавляет в запрос колонку с функцией замены значения NULL замещающим выражением.
Например, вместо:
можно записать:

Алгоритм реализации примера
1. Создайте веб-сервис — движок машинного обучения
Пример реализации веб-сервиса машинного обучения для ASP.Net Core 3.1 можно скачать по ссылке.
Реализуйте веб-сервис машинного-обучения MLService.
Задайте обязательные методы:
- /session/start
- /data/upload
- /session/info/get
- /fakeScorer/beginTraining
- /fakeScorer/predict
Полностью исходный код представлен ниже.
2. Расширьте список задач машинного обучения
Для расширения списка задач машинного обучения выполните следующие действия:
- Перейдите в дизайнер системы по кнопке
 . В блоке Настройка системы (System setup) перейдите по ссылке Справочники (Lookups).
. В блоке Настройка системы (System setup) перейдите по ссылке Справочники (Lookups). - Выберите справочник Задачи машинного обучения (ML problem types).
- Создайте новую запись.
Для записи установите:
- Название (Name) — "Fake scoring";
- Url сервиса (Service endpoint Url) — "http://localhost:5000/";
- Метод сервиса для обучения модели (Training endpoint) — "/fakeScorer/beginTraining".
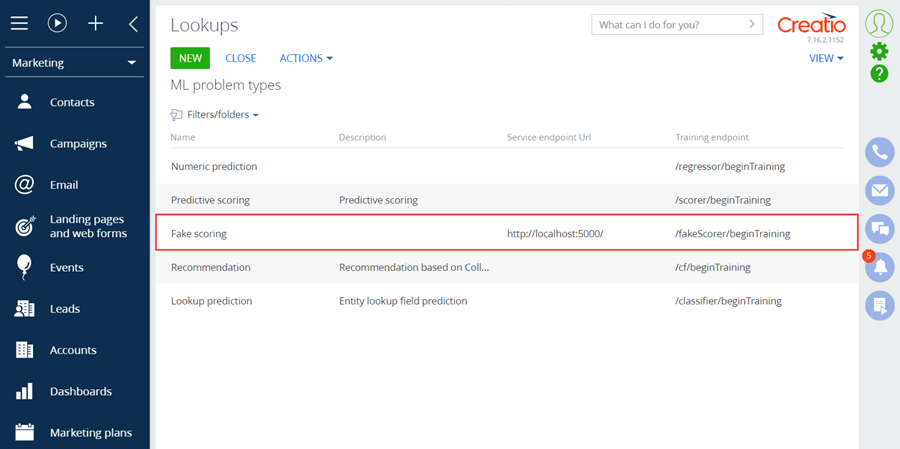
Идентификатор созданной записи — "319c39fd-17a6-453a-bceb-57a398d52636".
3. Реализуйте модель машинного обучения
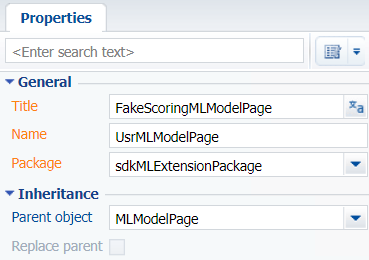
В разделе Конфигурация (Configuration) пользовательского пакета на вкладке Схемы (Schemas) выполните действие Добавить —> Схема модели представления карточки (Add —> Schema of Edit Page View Model). Созданный модуль должен наследовать функциональность базовой страницы модели машинного обучения MLModelPage, которая определена в пакете ML. Для этого укажите эту схему в качестве родительской для создаваемой схемы.
Для создаваемой схемы объекта установите:
- Заголовок (Title) — "FakeScoringMLModelPage";
- Название (Name) — "UsrMLModelPage".
- Родительский объект (Parent object) — выберите MLModelPage.
Переопределите базовый метод getIsScoring, чтобы вид создаваемой карточки соответствовал карточке базового предиктивного скоринга. Полностью исходный код представлен ниже.
После внесения изменений сохраните и опубликуйте схему.
В разделе Конфигурация (Configuration) пользовательского пакета на вкладке Схемы (Schemas) выполните действие Добавить —> Исходный код (Add —> Source Code).
Для создаваемой схемы объекта установите:
- Заголовок (Title) — "FakeScoringEntityPredictor";
- Название (Name) — "UsrFakeScoringEntityPredictor".
Реализуйте метод Predict, который получает данные, выгруженные из системы по объекту, и возвращает результат прогноза. Метод использует прокси-класс, реализующий интерфейс IMLServiceProxy, который упрощает вызов веб-сервиса.
Инициализируйте свойство ProblemTypeId идентификатором созданной записи в справочнике MLProblemType и реализуйте методы SaveEntityPredictedValues и SavePrediction. Полностью исходный код представлен ниже.
После внесения изменений сохраните и опубликуйте схему.
В разделе Конфигурация (Configuration) пользовательского пакета на вкладке Схемы (Schemas) выполните действие Добавить —> Исходный код (Add —> Source Code).
Для создаваемой схемы объекта установите:
- Заголовок (Title) — "FakeScoringProxy";
- Название (Name) — "UsrFakeScoringProxy".
Расширьте существующий интерфейс IMLServiceProxy и его реализацию методом прогнозирования для текущей задачи. В частности класс MLServiceProxy содержит обобщенный метод Predict, который принимает контракты для входящих данных и результата прогнозирования.
Полностью исходный код представлен ниже.
После внесения изменений сохраните и опубликуйте схему.
В разделе Конфигурация (Configuration) пользовательского пакета на вкладке Схемы (Schemas) выполните действие Добавить —> Исходный код (Add —> Source Code).
Для создаваемой схемы объекта установите:
- Заголовок (Title) — "FakeBatchScorer";
- Название (Name) — "UsrFakeBatchScorer".
Для использования функциональности пакетного прогнозирования реализуйте интерфейс IMLBatchPredictor, методы FormatValueForSaving и SavePredictionResult.
Полностью исходный код представлен ниже.
После внесения изменений сохраните и опубликуйте схему.
Описание кейса
Реализовать автоматическое прогнозирование колонки Категория (AccountCategory) по значениям полей Страна (Country), Количество сотрудников (EmployeesNumber), Отрасль (Industry) во время сохранения записи контрагента. При этом должны выполняться следующие условия:
- Обучение модели необходимо формировать на основании записей о контрагентах за последние 90 дней.
- Переобучение производить каждые 30 дней.
- Допустимое значение точности прогнозирования для модели в целом — 0.6.
Алгоритм выполнения кейса
1. Обучение модели
Для обучения модели необходимо:
1. Добавить запись в справочник Модели машинного обучения (MLModel). Значения полей записи приведены в таблице 1.
| Поле | Значение |
|---|---|
| Название | Прогнозирование категории контрагента |
| Задача машинного обучения | Прогнозирование справочного поля |
| Идентификатор корневого объекта | Контрагент |
| Нижний порог допустимого качества | 0.6 |
| Частота переобучения | 30 |
| Метаданные выборки для обучения |
|
| Выражение для выборки данных обучения |
Примеры составления запросов можно посмотреть в статье Составление запросов на выборку данных для модели машинного обучения. |
| Флаг, включающий прогнозирование по модели | Отметить |
2. Выполнить действие Запланировать задание обучения моделей на странице справочника Модели машинного обучения (MLModel).
Далее необходимо подождать пока поле Статус обработки моделей пройдет цепочку значений DataTransfer, QueuedToTrain, Training, Done. Процесс ожидания может занять несколько часов (зависит от объема передаваемых данных и общей нагрузки на сервис предиктивных моделей).
2. Выполнение прогнозов
Для выполнения прогнозов необходимо:
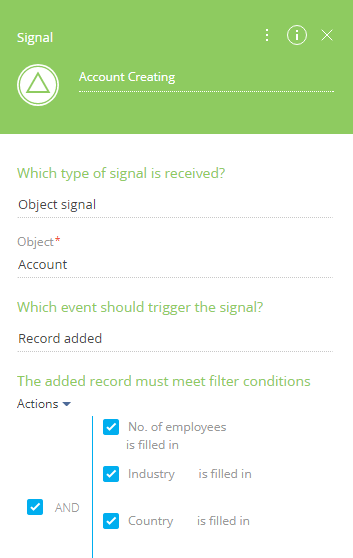
1. В пользовательском пакете создать бизнес-процесс, для которого стартовым сигналом будет событие сохранения объекта Контакт. При этом нужно проверить заполненность значениями необходимых полей (рис. 1).
2. В бизнес-процесс добавить параметр-справочник MLModelId, ссылающийся на сущность Модель машинного обучения. В качестве значения нужно выбрать запись с созданной моделью Прогнозирование категории Контрагента.
3. В бизнес-процесс добавить параметр-справочник RecordId, ссылающийся на сущность Контрагент. В качестве значения нужно выбрать ссылку на параметр RecordId элемента Сигнал.
4. На диаграмму бизнес-процесса добавить элемент Задание-сценарий и добавить в него следующий исходный код:
После сохранения и компиляции процесса для новых контрагентов будет выполнятся прогнозирование. Полученный прогноз будет отображаться на странице контрагента.
Интерфейсы IJobExecutor, IMLModelTrainerJob используются для задания синхронизации моделей.
Оркестрирует обработку моделей на стороне Creatio, запуская сессии передачи данных, стартуя обучения, а также проверяя статус моделей, обрабатываемых сервисом. Экземпляры по умолчанию запускаются планировщиком заданий через стандартный метод Execute интерфейса IJobExecutor.
Методы
Виртуальный метод, инкапсулирующий логику синхронизации. Базовая реализация этого метода выполняет следующую последовательность действий:
-
Выборка моделей для обучения — отбираются записи из MLModel по следующему фильтру:
- поля MetaData и TrainingSetQuery заполнены.
- поле Status находится в состоянии NotStarted, Done, Error или не заполнено.
- TrainFrequency больше 0.
- От даты последней попытки обучения (TriedToTrainOn) прошло TrainFrequency дней.
Для каждой записи этой выборки производится передача данных в сервис с помощью тренера предиктивной модели (см. ниже).
- Выборка ранее отправленных на обучение моделей и, при необходимости, обновление их статуса.
По каждой подходящей модели начинается сессия передачи данных по выборке. В процессе сессии пакетами по 1000 записей отправляются данные. Для каждой модели объем выборки ограничивается до 75 000 записей.
Интерфейс IMLModelTrainer является тренером предиктивной модели.
Отвечает за общую обработку отдельно взятой модели на этапе обучения. Коммуникация с сервисом обеспечивается с помощью прокси к предиктивному сервису (см. ниже).
Методы
Устанавливает сессию обучения для модели.
Передает данные в соответсвии с выборкой модели пакетами по 1000 записей. Выборка ограничивается объемом в 75 000 записей.
Обозначает завершение передачи данных и сообщает сервису о необходимости постановки модели в очередь обучения.
Запрашивает у сервиса текущее состояние модели и при необходимости обновляет Status.
Если обучение было успешным (Status содержит значение Done), то сервис возвращает метаданные по обученному экземпляру, в частности — точность получившегося экземпляра. Если точность выше или равна нижнему порогу (MetricThreshold) — идентификатор нового экземпляра записывается в поле ModelInstanceUId.
Интерфейс IMLServiceProxy является прокси к предиктивному сервису. Класс-обертка для http-запросов к предиктивному сервису.
Методы
Передает пакет данных для сессии обучения.
Вызывает сервис постановки обучения в очередь.
Запрашивает у сервиса текущее состояние для сессии обучения.
Вызывает для ранее обученного экземпляра модели сервис прогнозирования значения поля для отдельно взятого набора значений полей. В параметре Dictionary data в качестве ключа передается имя поля, которое обязательно должно совпадать с именем, указанным в поле MetaData справочника моделей. При успешном результате метод возвращает список значений типа ClassificationResult.
Свойства типа ClassificationResult
Значение поля.
Вероятность данного значения в диапазоне [0:1]. Сумма вероятностей для одного списка результатов близка к 1 (значения около 0 могут быть опущены).
Уровень важности данного прогноза.
| High | Данное значение поля имеет явное преимущество по сравнению с другими значениями из списка. Такой уровень может быть только у одного элемента в списке предсказанных. |
| Medium | Значение поля близко к нескольким другим высоким значениям в списке. Например, два значения в списке имеют вероятность 0,41 и 0,39, все остальные значительно меньше. |
| None | Нерелевантные значения с низкими вероятностями. |
Утилитный класс, помогающий для отдельной сущности произвести прогнозирование значения поля по указанной модели (одной или нескольким).
Методы
По Id модели и Id сущности выполняет прогнозирование и записывает результат в результирующее поле объекта. Работает с любой задачей машинного обучения: классификация, скоринг, прогнозирование числового поля.
По Id модели (или списку нескольких моделей, созданных для одного и того же объекта) и Id сущности выполняет классификацию и возвращает словарь, ключ которого — объект модели, значения — список спрогнозированных результатов.
Утилитный класс, помогающий сохранить результаты прогнозирования в объект системы.
Методы
Сохраняет результаты классификации (MLEntityPredictor.ClassifyEntityValues) в объект системы. По умолчанию сохраняет только результат, у которого Significance равен “High”. Но есть возможность переопределить это поведение с помощью переданного делегата onSetEntityValue. Если делегат вернет false, то значение не будет записано в объект системы.
Содержит информацию о выбранных данных для модели, периоде обучения, текущем статусе обучения и т.д.
Поля справочника MLModel
Назначение основных полей справочника MLModel приведено в таблице.
| Поле | Тип данных | Назначение | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Строка | Название модели. | ||||||||||
| ModelInstanceUId | Уникальный идентификатор | Идентификатор текущего экземпляра модели. | ||||||||||
| TrainedOn | Дата/время | Время, когда экземпляр был обучен. | ||||||||||
| TriedToTrainOn | Дата/время | Время последней попытки обучения. | ||||||||||
| TrainFrequency | Целое | Частота переобучения модели (дни). | ||||||||||
| MetaData | Строка |
Метаданные с типами колонок выборки. Записываются в JSON-формате следующей структуры: Здесь:
В описании колонок поддерживаются следующие атрибуты:
|
||||||||||
| TrainingSetQuery | Строка |
C#-выражение выборки тренировочных данных. Данное выражение должно возвращать экземпляр класса Terrasoft.Core.DB.Select. |
||||||||||
| RootSchemaUId | Уникальный идентификатор | Ссылка на схему объекта, для которого будет выполняться прогноз. | ||||||||||
| Status | Строка | Статус обработки модели (передача данных, обучение, готова для прогноза). | ||||||||||
| InstanceMetric | Число | Метрика качества для текущего экземпляра модели. | ||||||||||
| MetricThreshold | Число | Нижний порог допустимого качества модели. | ||||||||||
| PredictionEnabled | Логическое | Флаг, включающий прогнозирование по данной модели. | ||||||||||
| TrainSessionId | Уникальный идентификатор | Текущая сессия обучения. | ||||||||||
| MLProblemType | Уникальный идентификатор | Задача машинного обучения (определяет алгоритм и service url, с помощью которого будет обучаться модель). |