









Сервис машинного обучения
Glossary Item Box

Общие положения
Сервис машинного обучения (сервис прогнозирования значений справочного поля) использует методы статистического анализа для обучения на основании набора исторических данных. Историческими данными могут быть, например, обращения в службу поддержки за год. При этом используется текст обращения, а также дата и категория контрагента. Результирующим является поле [Группа ответственных].
Схема взаимодействия bpm’online с сервисом прогнозирования
Существует два основных этапа работы bpm’online для каждой модели: обучение и прогнозирование.
Модель прогнозирования — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное решение на основе исторических данных.
Обучение
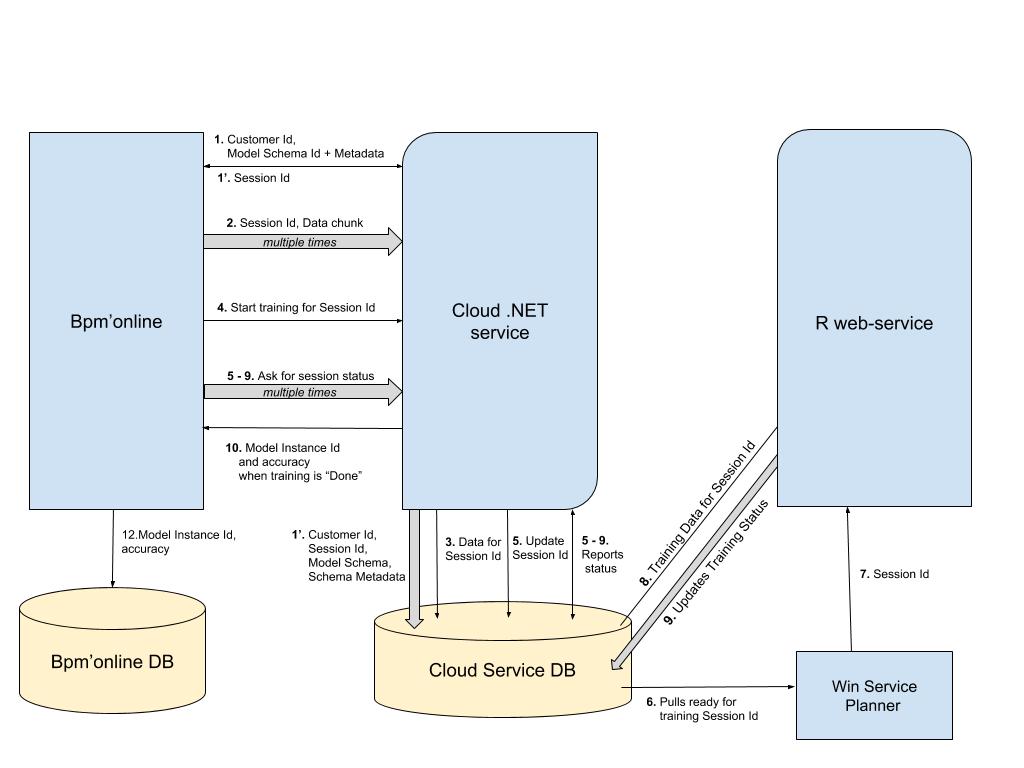
На этапе обучения выполняется "тренировка" сервиса (рис. 1). Основные шаги обучения:
- Установление сессии передачи данных и обучения.
- Последовательная выборка порции данных для модели и их загрузка в сервис.
- Запрос на постановку в очередь для обучения.
- Training engine для обучения модели обрабатывает очередь, обучает модель и сохраняет ее параметры во внутреннее хранилище.
- Bpm’online периодически опрашивает сервис для получения статуса модели.
- Как только для статуса модели установлено значение Done — модель готова для прогнозирования.
Рис. 1. — Схема взаимодействия bpm'online с сервисом на этапе обучения
Прогнозирование
Задача прогнозирования выполняется через вызов облачного сервиса с указанием Id экземпляра модели и данных для прогноза. Результат работы сервиса — набор значений с вероятностями, который сохраняется в bpm'online в таблице MLPrediction.
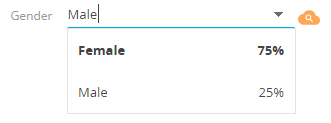
Если существует прогноз в таблице MLPrediction по определенной записи сущности, то на странице редактирования автоматически отображаются спрогнозированные значения для поля (рис. 2).
Рис. 2. — Отображение прогнозируемых значений
Настройки и типы данных bpm'online для работы с сервисом прогнозирования
Настройки bpm'online
Для работы с сервисом прогнозирования в bpm'online предусмотрены следующие данные.
- Системная настройка CloudServicesAPIKey — отвечает за аутентификацию экземпляра bpm’online в облачных сервисах.
- Запись в справочнике [Задачи машинного обучения] (MLProblemType) с заполненным полем [ServiceUrl] — адрес развернутого сервиса прогнозирования.
- Записи о моделях в справочнике [Модель машинного обучения] (MLModel), содержащие информацию о выборке данных для модели, периодичности обучения, текущем состоянии обучения и т. п. Для каждой модели в поле MLProblemType должна быть указана ссылка на корректную запись справочника [Задачи машинного обучения].
- Системная настройка MLModelTrainingPeriodMinutes — определяет периодичность запуска синхронизации моделей.
Справочник MLModel
Назначение основных полей справочника MLModel приведено в таблице 1.
Табл. 1. — Основные поля справочника MLModel
| Поле | Тип данных | Назначение |
|---|---|---|
| Name | Строка | Название модели. |
| ModelInstanceUId | Уникальный идентификатор | Идентификатор текущего экземпляра модели. |
| TrainedOn | Дата/время | Время, когда экземпляр был обучен. |
| TriedToTrainOn | Дата/время | Время последней попытки обучения. |
| TrainFrequency | Целое | Частота переобучения модели (дни). |
| MetaData | Строка |
Метаданные с типами колонок выборки. Записываются в JSON-формате следующей структуры:
{
inputs: [
{
name: "Имя поля 1 в выборке данных",
type: "Text",
isRequired: true
},
{
name: "Имя поля 2 в выборке данных",
type: "Lookup"
},
//...
],
output: {
name: "Результирующее поле",
type: "Lookup",
displayName: "Имя колонки для отображения"
}
}
Здесь:
В описании колонок поддерживаются следующие атрибуты:
|
| TrainingSetQuery | Строка |
C#-выражение выборки тренировочных данных. Данное выражение должно возвращать экземпляр класса Terrasoft.Core.DB.Select. Например: (Select)new Select(userConnection) .Column("Id") .Column("Symptoms") .Column("CreatedOn") .From("Case", "c") .OrderByDesc("c", "CreatedOn") ВАЖНО В выражении для выборки обязательно должна выбираться колонка типа "Уникальный идентификатор. Эта колонка должна называться или иметь псевдоним Id. ВАЖНО Если выражение для выборки содержит колонку для сортировки, то эта колонка обязательно должна присутствовать в результирующей выборке. Примеры составления запросов можно посмотреть в статье "Составление запросов на выборку данных для модели машинного обучения". |
| RootSchemaUId | Уникальный идентификатор | Ссылка на схему объекта, для которого будет выполняться прогноз. |
| Status | Строка | Статус обработки модели (передача данных, обучение, готова для прогноза). |
| InstanceMetric | Число | Метрика качества для текущего экземпляра модели. |
| MetricThreshold | Число | Нижний порог допустимого качества модели. |
| PredictionEnabled | Логическое | Флаг, включающий прогнозирование по данной модели. |
| TrainSessionId | Уникальный идентификатор | Текущая сессия обучения. |
| MLProblemType | Уникальный идентификатор | Задача машинного обучения (определяет алгоритм и service url, с помощью которого будет обучаться модель). |
Набор классов для обучения
MLModelTrainerJob: IJobExecutor, IMLModelTrainerJob — задание синхронизации моделей
Оркестрирует обработку моделей на стороне bpm’online, запуская сессии передачи данных, стартуя обучения, а также проверяя статус моделей, обрабатываемых сервисом. Экземпляры по умолчанию запускаются планировщиком заданий через стандартный метод Execute интерфейса IJobExecutor.
Публичные методы:
IMLModelTrainerJob.RunTrainer() — виртуальный метод, инкапсулирующий логику синхронизации. Базовая реализация этого метода выполняет следующую последовательность действий:
1. Выборка моделей для обучения — отбираются записи из MLModel по следующему фильтру:
- поля MetaData и TrainingSetQuery заполнены.
- поле Status находится в состоянии NotStarted, Done, Error или не заполнено.
- TrainFrequency больше 0.
- От даты последней попытки обучения (TriedToTrainOn) прошло TrainFrequency дней.
Для каждой записи этой выборки производится передача данных в сервис с помощью тренера предиктивной модели (см. ниже).
2. Выборка ранее отправленных на обучение моделей и, при необходимости, обновление их статуса.
По каждой подходящей модели начинается сессия передачи данных по выборке. В процессе сессии пакетами по 1000 записей отправляются данные. Для каждой модели объем выборки ограничивается до 75 000 записей.
MLModelTrainer: IMLModelTrainer — Тренер предиктивной модели
Отвечает за общую обработку отдельно взятой модели на этапе обучения. Коммуникация с сервисом обеспечивается с помощью прокси к предиктивному сервису (см. ниже).
Публичные методы:
IMLModelTrainer.StartTrainSession() — устанавливает сессию обучения для модели.
IMLModelTrainer.UploadData() — передает данные в соответсвии с выборкой модели пакетами по 1000 записей. Выборка ограничивается объемом в 75 000 записей.
IMLModelTrainer.BeginTraining() — обозначает завершение передачи данных и сообщает сервису о необходимости постановки модели в очередь обучения.
IMLModelTrainer.UpdateModelState — запрашивает у сервиса текущее состояние модели и при необходимости обновляет Status.
Если обучение было успешным (Status содержит значение Done), то сервис возвращает метаданные по обученному экземпляру, в частности — точность получившегося экземпляра. Если точность выше или равна нижнему порогу (MetricThreshold) — идентификатор нового экземпляра записывается в поле ModelInstanceUId.
MLServiceProxy: IMLServiceProxy — прокси к предиктивному сервису
Класс-обертка для http-запросов к предиктивному сервису.
Публичные методы:
IMLServiceProxy.UploadData() — передает пакет данных для сессии обучения.
IMLServiceProxy.BeginTraining() — вызывает сервис постановки обучения в очередь.
IMLServiceProxy.GetTrainingSessionInfo() — запрашивает у сервиса текущее состояние для сессии обучения.
IMLServiceProxy.Classify(Guid modelInstanceUId, Dictionary<string, object> data) — вызывает для ранее обученного экземпляра модели сервис прогнозирования значения поля для отдельно взятого набора значений полей. В параметре Dictionary data в качестве ключа передается имя поля, которое обязательно должно совпадать с именем, указанным в поле MetaData справочника моделей. При успешном результате метод возвращает список значений типа ClassificationResult.
Основные свойства типа ClassificationResult:
- Value — значение поля.
- Probability — вероятность данного значения в диапазоне Array. Сумма вероятностей для одного списка результатов близка к 1 (значения около 0 могут быть опущены).
-
Significance — уровень важности данного прогноза. Это строковое перечисление со следующими вариантами:
- High — данное значение поля имеет явное преимущество по сравнению с другими значениями из списка. Такой уровень может быть только у одного элемента в списке предсказанных.
- Medium — значение поля близко к нескольким другим высоким значениям в списке. Например, два значения в списке имеют вероятность 0,41 и 0,39, все остальные значительно меньше.
- None — нерелевантные значения с низкими вероятностями.
Расширение логики обучения модели
Описанная выше цепочка классов вызывает и создает экземпляры друг друга посредством IOC контейнера Terrasoft.Core.Factories.ClassFactory.
Если необходимо заместить логику какого-либо компонента, то нужно реализовать соответствующий интерфейс. При запуске приложения следует выполнить привязку интерфейса в собственной реализации.
Интерфейсы для расширения логики:
IMLModelTrainerJob — реализация этого интерфейса позволит изменить набор моделей для обучения.
IMLModelTrainer — отвечает за логику загрузки данных для обучения и обновления статуса моделей.
IMLServiceProxy — реализация этого интерфейса позволит выполнять запросы к произвольному предиктивному сервису.
Вспомогательные классы для прогнозирования
Вспомогательные (утилитные) классы для прогнозирования позволяют реализовать два базовых кейса:
- Прогнозирование в момент создания или обновления записи какой-либо сущности на сервере.
- Прогнозирование при изменении сущности на странице редактирования.
В случае прогнозирования на стороне сервера bpm'online — создается бизнес-процесс, который реагирует на сигнал создания/изменения сущности, вычитывает набор полей и вызывает сервис прогнозирования. При получении корректного результата он сохраняет набор значений поля с вероятностями в таблицу MLClassificationResult. При необходимости бизнес-процесс записывает отдельное значение (например, с наибольшей вероятностью) в соответствующее поле сущности.
MLEntityPredictor
Утилитный класс, помогающий для отдельной сущности произвести прогнозирование значения поля по указанной модели (одной или нескольким).
Некоторые публичные методы:
PredictEntityValueAndSaveResult(Guid modelId, Guid entityId) — по Id модели и Id сущности выполняет прогнозирование и записывает результат в результирующее поле объекта. Работает с любой задачей машинного обучения: классификация, скоринг, прогнозирование числового поля.
ClassifyEntityValues(List<Guid> modelIds, Guid entityId) — по Id модели (или списку нескольких моделей, созданных для одного и того же объекта) и Id сущности выполняет классификацию и возвращает словарь, ключ которого — объект модели, значения — список спрогнозированных результатов
MLPredictionSaver
Утилитный класс, помогающий сохранить результаты прогнозирования в объект системы.
Некоторые публичные методы:
SaveEntityPredictedValues(Guid schemaUId, Guid entityId, Dictionary<MLModelConfig, List<ClassificationResult>> predictedValues, Func<Entity, string, ClassificationResult, bool> onSetEntityValue) — сохраняет результаты классификации (MLEntityPredictor.ClassifyEntityValues) в объект системы. По умолчанию сохраняет только результат, у которого Significance равен “High”. Но есть возможность переопределить это поведение с помощью переданного делегата onSetEntityValue. Если делегат вернет false, то значение не будет записано в объект системы.