



Прогнозирование значения справочного поля
Вы можете создать модель машинного обучения, которая будет выполнять прогнозирование значения заданного справочного поля. Поле будет заполняться автоматически на основании данных текущей записи и решений, принятых пользователями ранее в аналогичных ситуациях.
Пример
Необходимо настроить модель, которая будет предсказывать наиболее вероятную категорию контрагента.
I. Создание модели прогнозирования значения справочного поля
1.Перейдите в дизайнер системы по кнопке  .
.
2.Откройте раздел [Модели машинного обучения] и нажмите кнопку [Добавить].
3.Заполните мини-карточку создания модели (Рис. 1).
Рис. 1 — Мини-карточка создания модели прогнозирования значения справочного поля
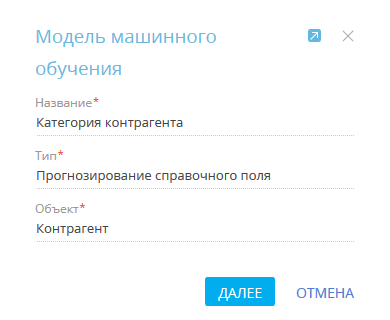
a.[Название] — введите название модели, по которому ее будет легко найти в реестре раздела [Модели машинного обучения] и при настройке элемента [Прогнозирование данных].
b.[Тип] — укажите задачу, которую необходимо решить при помощи модели машинного обучения. Например, “Прогнозирование справочного поля”.
c.[Объект] — выберите объект, по записям которого будет выполняться прогнозирование. Например, для использования модели в разделе [Контрагенты] выберите объект “Контрагент”.
II. Параметры модели прогнозирования значения справочного поля
После заполнения обязательных полей перейдите на вкладку [Параметры] и укажите дополнительные параметры модели (Рис. 2):
Рис. 2 — Дополнительные параметры модели машинного обучения
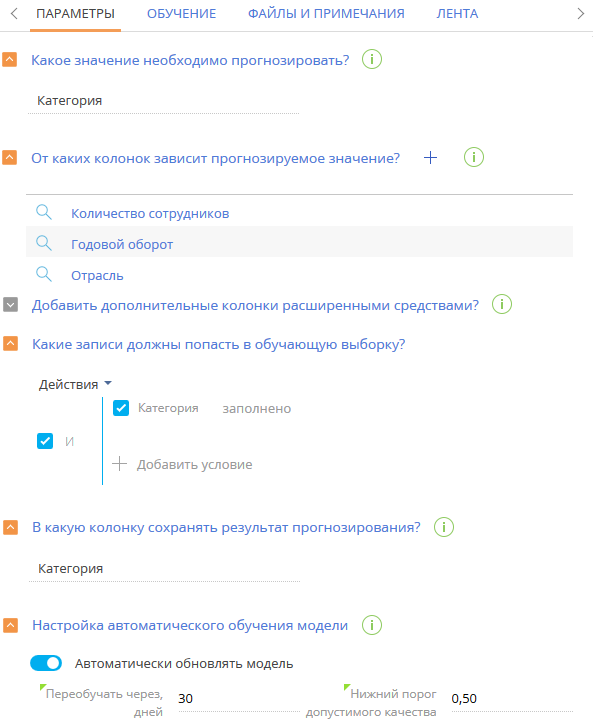
1.[Какое значение необходимо прогнозировать?] — выберите поле, для которого будет выполняться прогнозирование значения. В списке представлены все справочные поля, которые есть на странице указанного объекта. Например, для прогнозирования категории контрагента выберите из списка поле [Категория]. В результате прогнозирования поле будет автоматически заполнено одним из значений справочника [Категории контрагентов].
2.[От каких колонок зависит прогнозируемое значение?] — укажите колонки, которые будут использоваться системой для определения алгоритмов поведения, связанных с прогнозируемым полем. Например, если обычно вы определяете категорию контрагента, исходя из количества сотрудников, оборота и отрасли, в которой работает контрагент, — укажите колонки [Количество сотрудников], [Годовой оборот] и [Отрасль]. Система изучит значения этих колонок в исторических записях и их соотношение со значениями колонки [Категория].
3.[Добавить дополнительные колонки расширенными средствами?] — можно также написать запрос, который расширит список колонок, учитываемых при обучении модели. Написание запроса выполняется разработчиком. Подробнее о написании запросов для моделей машинного обучения читайте в статье “Составление запросов на выборку данных для модели машинного обучения” документации по разработке.
4.[Какие записи должны попасть в обучающую выборку?] — настройте фильтр для формирования выборки данных, на которых будет обучаться модель. Система использует эти записи для определения соотношения прогнозируемого значения и колонок, на которых основывается прогноз. Например, для обучения модели определения категории контрагента необходимо использовать только те записи раздела [Контрагенты], где заполнено поле [Категория].
На заметку
Для обучения модели вы можете указывать колонки как текущего, так и связанных объектов.
5.[В какую колонку сохранять результат прогнозирования?] — обычно прогнозное значение сохраняется в колонку, значение которой требовалось предсказать. Если вы не хотите, чтобы система изменяла значение прогнозируемой колонки, укажите другую колонку для сохранения прогноза.
6.Заполните настройки автоматического обучения модели. Creatio будет периодически проводить переобучение модели на обновленных исторических данных.
a.В поле [Переобучать через, дней] укажите длительность перерыва между переобучениями. По истечении указанного количества дней модель будет отправлена на переобучение с использованием исторических данных, которые соответствуют настроенным фильтрам. Первое переобучение модели выполняется автоматически после установки признака [Автоматически обновлять модель].
b.В поле [Нижний порог допустимого качества] укажите наименьшее допустимое значение точности прогноза. При первом обучении модели это значение определит точность прогноза, по достижении которой экземпляры модели могут применяться для работы в системе. Экземпляры, не достигшие нижнего порога допустимого качества, системой не используются. Рекомендуется указывать нижний порог допустимого качества более 0,5. Точность прогноза варьируется от 0,00 до 1,00, где 1,00 — это максимально точный прогноз, а 0,00 — наименее точный. Точность прогноза рассчитывается как отношение количества правильно спрогнозированных значений к общему количеству исторических данных, на которых проводилось обучение. Подробно о механизме расчета точности прогнозов читайте в документации Google.
На заметку
Качество прогнозов активной модели может ухудшиться при переобучении, например, в тех случаях, когда значения колонок, указанных в поле [От каких колонок зависит погнозируемое значение?], не заполняются при создании новых записей. Чтобы избежать понижения точности прогнозов, перед запуском переобучения модели убедитесь, что список колонок, используемых для обучения модели, актуален.
III. Расширенные настройки модели прогнозирования значения справочного поля
Перейдите на вкладку [Расширенные настройки], если вы хотите указать дополнительные параметры модели прогнозирования.
1.В области [Добавить дополнительные колонки расширенными средствами?] вы можете средствами разработки сформировать запрос на выборку дополнительных колонок, от которых зависит прогнозируемое значение. Подробнее читайте в статье “Составление запросов на выборку данных для модели машинного обучения”.
2.В группе полей [Расширенные параметры модели] значения заполняются автоматически. При необходимости вы можете их редактировать и заменять другими значениями.
a.[Минимальное количество записей для обучения] — минимальное количество записей, на основании которых может проводиться обучение модели. Если в системе недостаточно исторических записей, то обучение не будет выполнено.
b.[Максимальное количество записей для обучения] — максимальное количество записей, на основании которых может проводиться обучение модели. Если в выборку по настроенному фильтру попадает больше записей, чем указано в этом поле, то будет взято то количество, которое указано в поле, остальные записи будут отсечены.
c.[Метод выбора прогнозируемого значения] — алгоритм заполнения полей прогнозируемыми значениями.
•“Значимость, определяемая движком ML” — алгоритм, который определяет уверенность прогноза на уровне сервиса машинного обучения. Если у одного из значений уверенность высокая, а у других низкая, то поле заполняется автоматически значением с высокой уверенностью. Если у нескольких значений уверенность высокая или у всех низкая, то поле не заполнится, но модель создаст список рекомендаций для заполнения.
•“Максимальная вероятность” — алгоритм, который определяет, соответствует ли вероятность прогноза указанному для нее нижнему пределу. Если вероятность равна значению нижнего предела или превышает его, то поле будет заполнено автоматически. Если уверенность прогноза ниже значения порога допустимого качества, то поле не заполнится, но модель создаст список рекомендаций для заполнения. При выборе этого алгоритма появится дополнительное поле [Нижний предел вероятности для выбора прогнозируемого значения], в котором необходимо указать минимально допустимую вероятность прогноза, от 0 до 1.
3.Нажмите кнопку [Сохранить].
4.После настройки модели нажмите кнопку [Обучить модель] для начала процесса обучения. Результат обучения можно посмотреть на вкладке [Обучение] и в статусе модели в реестре раздела (Рис. 3).
Рис. 3— Отображение статуса моделей в реестре раздела [Модели машинного обучения]
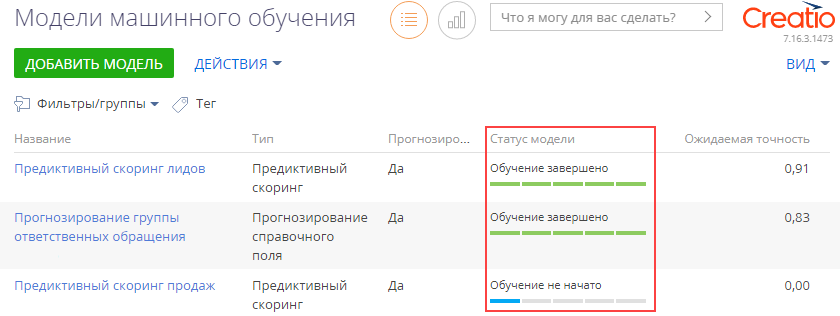
5.Если вы планируете доработку модели, то снимите признак [Прогнозирование активно]. Рекомендуется полностью настроить модель перед активацией прогнозирования. Прогнозирование в разделе будет выполняться только после того, как будет получен экземпляр модели, точность прогнозов которого превышает нижний порог допустимого качества.
В результате в Creatio будет создана новая модель. При запуске бизнес-процесса будет производиться прогнозирование и автозаполнение полей для выбранных записей.
В нашем примере модель прогнозирования категории контрагента проанализирует значения колонок [Количество сотрудников], [Годовой оборот] и [Отрасль] для контрагентов, у которых заполнена колонка [Категория]. Чем больше исторических данных используется для обучения модели, тем выше точность прогноза.
После получения экземпляра модели с достаточно высокой точностью прогноза в разделе будет доступно прогнозирование категории контрагента на основании данных в полях [Количество сотрудников], [Годовой оборот] и [Отрасль].
На заметку
Получить информацию об истории обучения модели в целом и каждого сеанса переобучения в отдельности вы можете на вкладке [Обучение] страницы модели.
Смотрите также
•Основные термины предиктивного анализа данных
•Прогнозирование значения числового поля
•Прогнозирование рейтинга записей
•Рекомендательное прогнозирование